今天晚上,OpenAI的CEO Sam Altman突然放出了大家期待已久的大招:
ChatGPT将在未来几周内开放语音和视觉功能,也就是官方形容的,ChatGPT现在能看,能听,能说了。
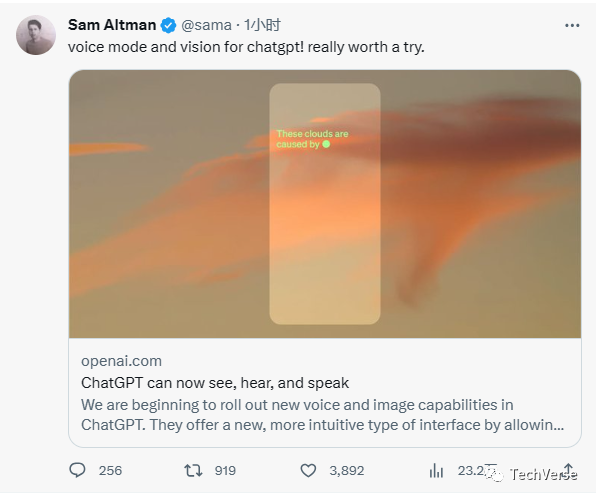
并且放出了一个非常直观的视频,展示ChatGPT的视觉能力
自动播放AI相关的自媒体迅速行动起来抢热点,这是难得的爆炸新闻,还有官方的视频素材,(可惜TechVerse今天推送过文章,所以只能在今天凌晨发出这篇文章)。
但是,在无法第一时间抢热点的焦虑中度过一段时间后,我发现,除了自媒体们,大家并没有想象的激动,我也没有在朋友圈看到刷屏的自行车。没有了转发的“魔法”,“革命”,”太强了“, AI也开始经历Web3的旅程,变得没人关心了。
这其中的原因,被大家讨论过很多遍了,过高的预期和今天AI的能力限制的矛盾,让越来越多的人不再那么兴奋,可是今天这样的大招都没能掀起刷屏,也着实让人惊讶,AI凉的速度之快。但是,科技的浪潮就是在这样的泡沫和低谷中交替前进的,今天发布的新功能,可能正是解锁LLM场景的一把钥匙:

概括一下ChatGPT发布的功能:
OpenAI正在ChatGPT中推出新的语音和图像功能。这些新功能提供了更直观的交互方式,允许用户与ChatGPT进行语音对话或向其展示正在讨论的内容。
主要值得关注的点包括:
用户现在可以与ChatGPT进行语音交谈,它可以回复你。这个新功能由文本转语音模型提供支持,可以从文本和少量语音样本生成逼真的语音。
用户现在可以在ChatGPT中展示一张或多张图像,以获取相关帮助和见解。在移动应用上,可以使用绘图工具聚焦图像的特定部分。这些视觉能力由多模态GPT-3.5和GPT-4提供支持。
OpenAI正逐步推出这些新功能,以进行改进和风险缓解,并准备用户使用更强大的系统。考虑到语音和视觉能力带来的新风险,这种渐进策略尤为重要。
其中,官方给出了一些可能的应用场景:
当旅行时,拍下一处地标的图片,并就其有趣之处进行语音交谈。
在家时,拍下冰箱和食品柜的图片,弄清做什么晚餐(并提出后续问题获取步骤式食谱)。
晚餐后,通过拍照、圈画题目,并与孩子共享提示,帮助孩子解决数学问题。
也包括视频中的案例,指导用户选择正确的工具调节自行车座椅的高度。

这些场景,实际上就是一个原生的AR AI助手需要的功能!如果用户佩戴一副有摄像头的智能眼镜,今天,LLM第一次可以就像一个万能的助理,通过自己的眼睛和用户分享同样的信息,并且直接提供帮助。而语音的交互,可能更好的在这种场景实现输入和输出。
随着今年下半年Meta Quest3的发货和明年Vision Pro的发布,这也许会让LLM在XR设备中发挥更大的作用。让人类向虚拟世界更进一步了!
AI,凉一点,才有点靠谱的味道。
猜你喜欢
最新文章










- 开云体育官方版app:谁会是今年中超第一位下课的主帅?

2023-05-03 19:35:22
- 惠普今日发布了该公司的2022财年第三财季财报

2022-08-31 15:13:25
- MyFitnessPal将其流行的条形码扫描仪功能放在付费墙后面

2022-08-31 09:50:57
- 摩托罗拉系统收购无线电专家巴雷特

2022-08-30 14:12:44
- 安全hold公布2022年第二季度业绩

2022-08-29 14:47:40