原标题:老黄深夜炸场,世界最强AI芯片H200震撼发布!性能飙升90%,Llama 2推理速度翻倍,大批超算中心来袭
刚刚,英伟达发布了目前世界最强的AI芯片H200,性能较H100提升了60%到90%,还能和H100兼容。算力荒下,大科技公司们又要开始疯狂囤货了。
英伟达的节奏,越来越可怕了。
就在刚刚,老黄又一次在深夜炸场——发布目前世界最强的AI芯片H200!
较前任霸主H100,H200的性能直接提升了60%到90%。
不仅如此,这两款芯片还是互相兼容的。这意味着,使用H100训练/推理模型的企业,可以无缝更换成最新的H200。

全世界的AI公司都陷入算力荒,英伟达的GPU已经千金难求。英伟达此前也表示,两年一发布的架构节奏将转变为一年一发布。
就在英伟达宣布这一消息之际,AI公司们正为寻找更多H100而焦头烂额。
英伟达的高端芯片价值连城,已经成为贷款的抵押品。

谁拥有H100,是硅谷最引人注目的顶级八卦
至于H200系统,英伟达表示预计将于明年二季度上市。
同在明年,英伟达还会发布基于Blackwell架构的B100,并计划在2024年将H100的产量增加两倍,目标是生产200多万块H100。
而在发布会上,英伟达甚至全程没有提任何竞争对手,只是不断强调「英伟达的AI超级计算平台,能够更快地解决世界上一些最重要的挑战。」
随着生成式AI的大爆炸,需求只会更大,而且,这还没算上H200呢。赢麻了,老黄真的赢麻了!

141GB超大显存,性能直接翻倍!
H200,将为全球领先的AI计算平台增添动力。
它基于Hopper架构,配备英伟达H200 Tensor Core GPU和先进的显存,因此可以为生成式AI和高性能计算工作负载处理海量数据。
英伟达H200是首款采用HBM3e的GPU,拥有高达141GB的显存。

与A100相比,H200的容量几乎翻了一番,带宽也增加了2.4倍。与H100相比,H200的带宽则从3.35TB/s增加到了4.8TB/s。
英伟达大规模与高性能计算副总裁Ian Buck表示——
要利用生成式人工智能和高性能计算应用创造智能,必须使用大型、快速的GPU显存,来高速高效地处理海量数据。借助H200,业界领先的端到端人工智能超算平台的速度会变得更快,一些世界上最重要的挑战,都可以被解决。

Llama 2推理速度提升近100%
跟前代架构相比,Hopper架构已经实现了前所未有的性能飞跃,而H100持续的升级,和TensorRT-LLM强大的开源库,都在不断提高性能标准。
H200的发布,让性能飞跃又升了一级,直接让Llama2 70B模型的推理速度比H100提高近一倍!
H200基于与H100相同的Hopper架构。这就意味着,除了新的显存功能外,H200还具有与H100相同的功能,例如Transformer Engine,它可以加速基于Transformer架构的LLM和其他深度学习模型。

HGX H200采用英伟达NVLink和NVSwitch高速互连技术,8路HGX H200可提供超过32 Petaflops的FP8深度学习计算能力和1.1TB的超高显存带宽。
当用H200代替H100,与英伟达Grace CPU搭配使用时,就组成了性能更加强劲的GH200 Grace Hopper超级芯片——专为大型HPC和AI应用而设计的计算模块。

下面我们就来具体看看,相较于H100,H200的性能提升到底体现在哪些地方。
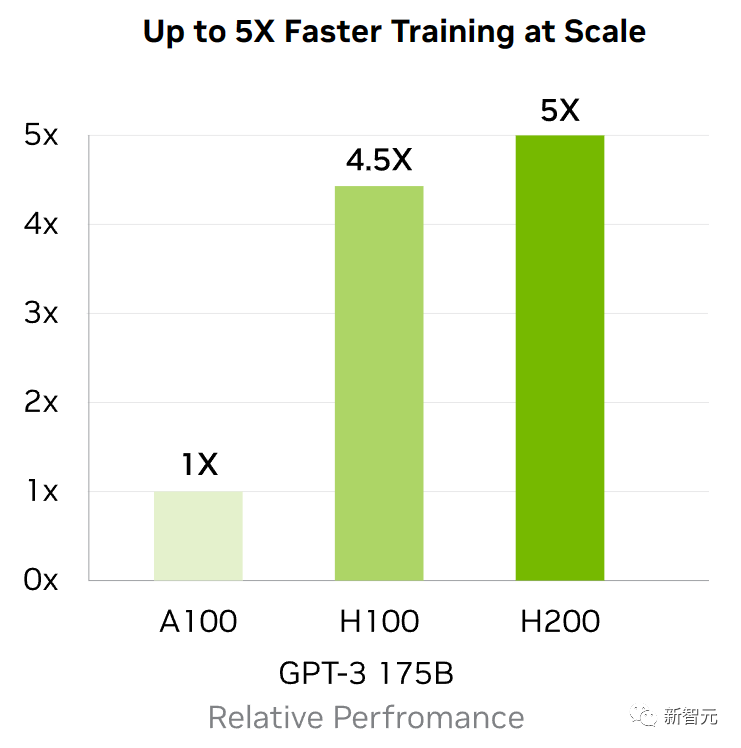
首先,H200的性能提升最主要体现在大模型的推理性能表现上。
如上所说,在处理Llama 2等大语言模型时,H200的推理速度比H100提高了接近1倍。

因为计算核心更新幅度不大,如果以训练175B大小的GPT-3为例,性能提升大概在10%左右。
显存带宽对于高性能计算(HPC)应用程序至关重要,因为它可以实现更快的数据传输,减少复杂任务的处理瓶颈。
对于模拟、科学研究和人工智能等显存密集型HPC应用,H200更高的显存带宽可确保高效地访问和操作数据,与CPU相比,获得结果的时间最多可加快110倍。
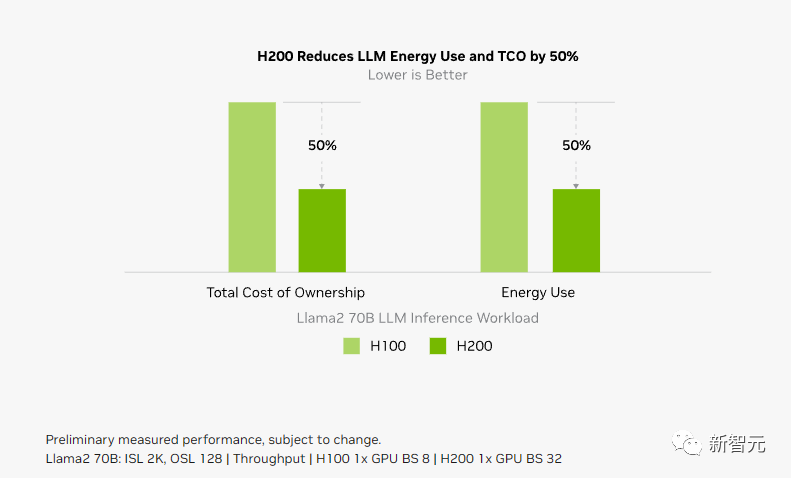
相较于H100,H200在处理高性能计算的应用程序上也有20%以上的提升。

而对于用户来说非常重要的推理能耗,H200相比H100直接腰斩。
这样,H200能大幅降低用户的使用成本,继续让用户「买的越多,省的越多」!
上个月,外媒SemiAnalysis曾曝出一份英伟达未来几年的硬件路线图,包括万众瞩目的H200、B100和「X100」GPU。
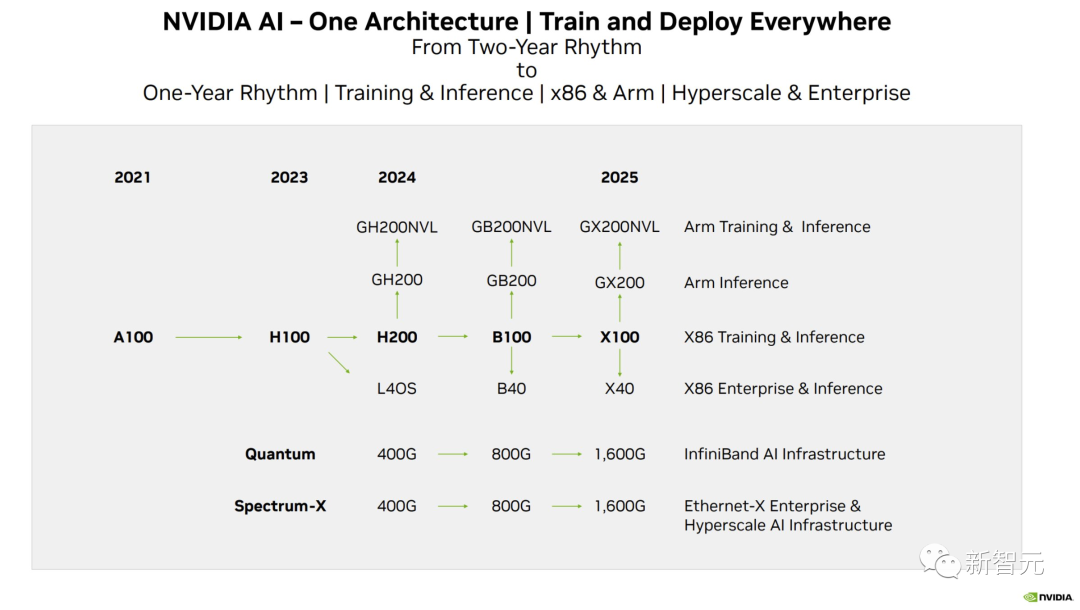
而英伟达官方,也公布了官方的产品路线图,将使用同一构架设计三款芯片,在明年和后年会继续推出B100和X100。
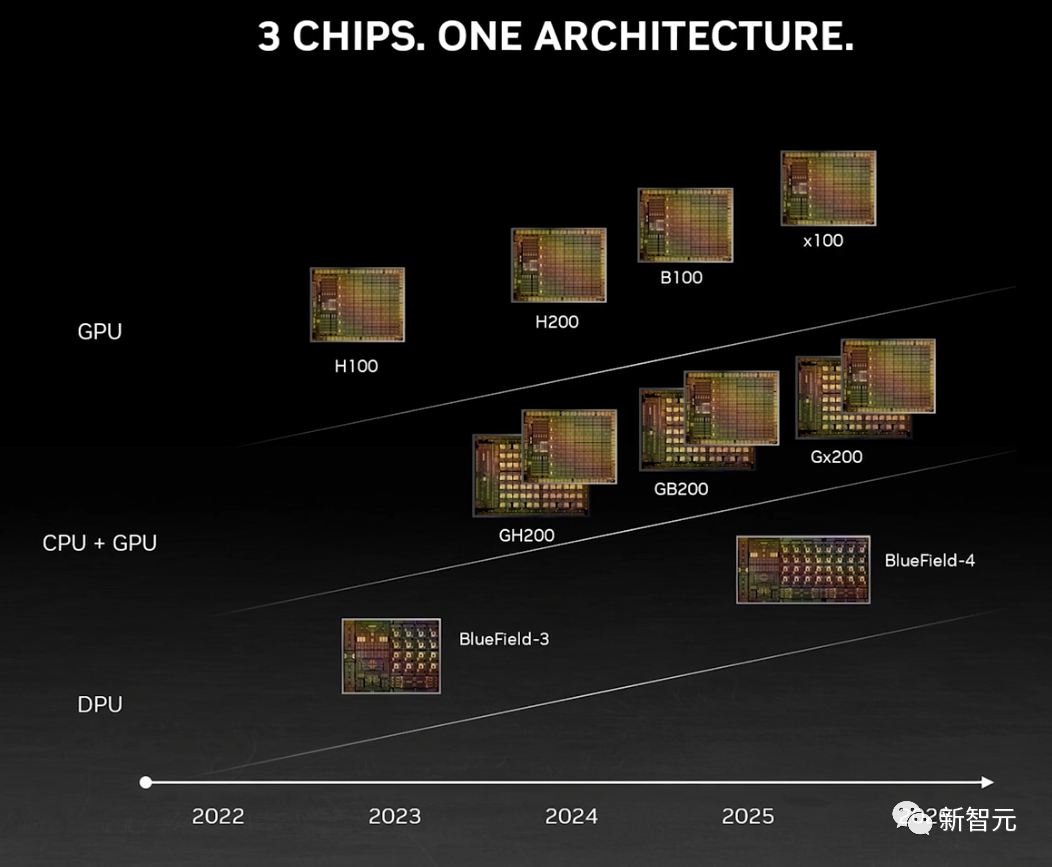
B100,性能已经望不到头了
这次,英伟达更是在官方公告中宣布了全新的H200和B100,将过去数据中心芯片两年一更新的速率直接翻倍。
以推理1750亿参数的GPT-3为例,今年刚发布的H100是前代A100性能的11倍,明年即将上市的H200相对于H100则有超过60%的提升,而再之后的B100,性能更是望不到头。
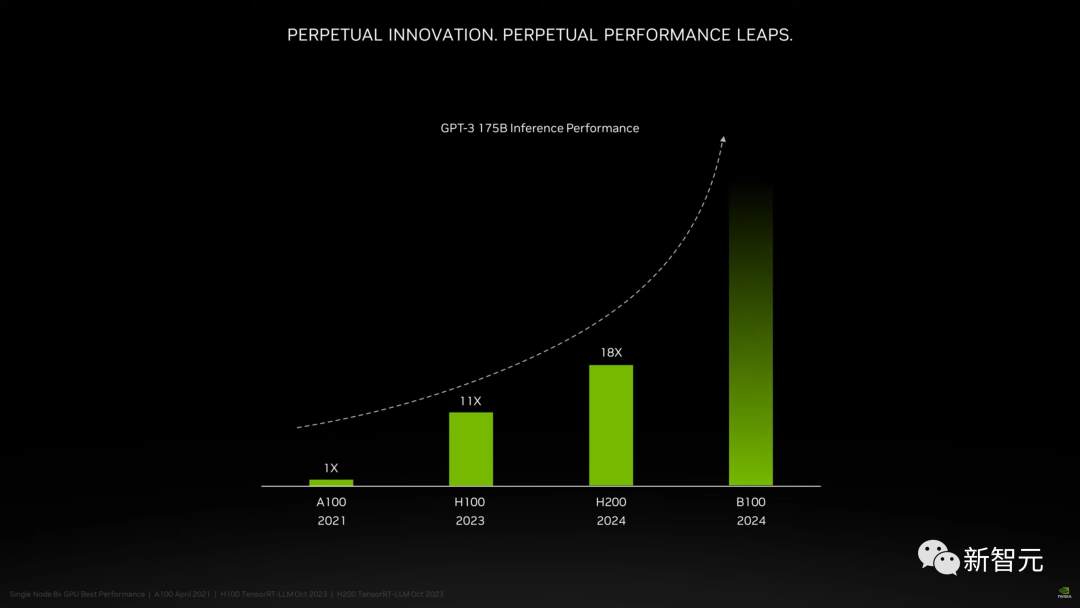
至此,H100也成为了目前在位最短的「旗舰级」GPU。
如果说H100现在就是科技行业的「黄金」,那么英伟达又成功制造了「铂金」和「钻石」。

H200加持,新一代AI超算中心大批来袭
云服务方面,除了英伟达自己投资的CoreWeave、Lambda和Vultr之外,亚马逊云科技、谷歌云、微软Azure和甲骨文云基础设施,都将成为首批部署基于H200实例的供应商。

此外,在新的H200加持之下,GH200超级芯片也将为全球各地的超级计算中心提供总计约200 Exaflops的AI算力,用以推动科学创新。

在SC23大会上,多家顶级超算中心纷纷宣布,即将使用GH200系统构建自己的超级计算机。
德国尤里希超级计算中心将在超算JUPITER中使用GH200超级芯片。
这台超级计算机将成为欧洲第一台超大规模超级计算机,是欧洲高性能计算联合项目(EuroHPC Joint Undertaking)的一部分。

Jupiter超级计算机基于Eviden的BullSequana XH3000,采用全液冷架构。
它总共拥有24000个英伟达GH200 Grace Hopper超级芯片,通过Quantum-2 Infiniband互联。
每个Grace CPU包含288个Neoverse内核, Jupiter的CPU就有近700万个ARM核心。
它能提供93 Exaflops的低精度AI算力和1 Exaflop的高精度(FP)算力。这台超级计算机预计将于2024年安装完毕。
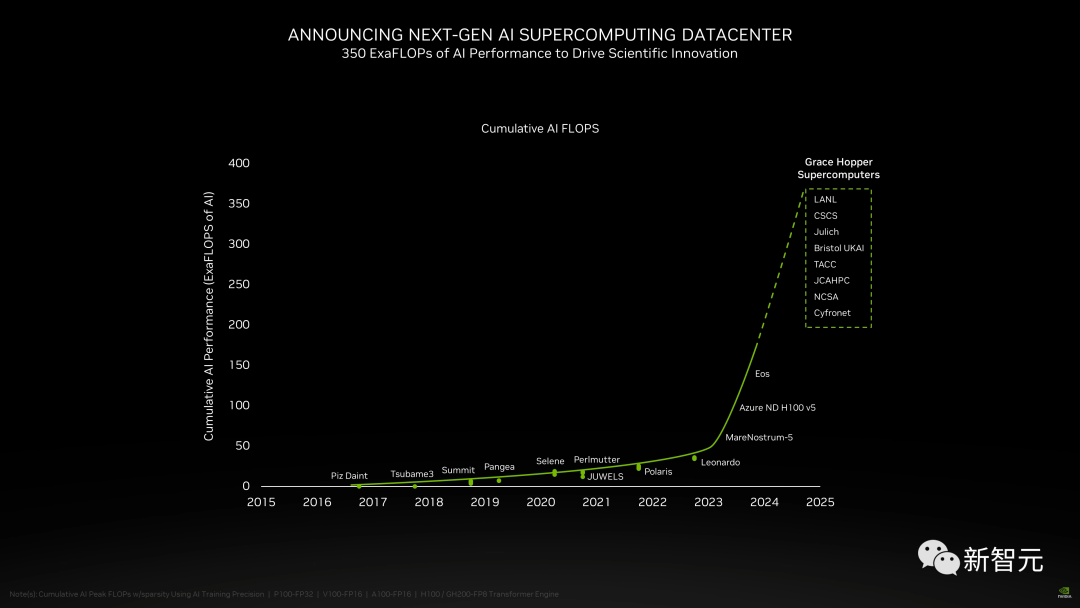
由筑波大学和东京大学共同成立的日本先进高性能计算联合中心,将在下一代超级计算机中采用英伟达GH200 Grace Hopper超级芯片构建。
作为世界最大超算中心之一的德克萨斯高级计算中心,也将采用英伟达的GH200构建超级计算机Vista。

诺伊大学香槟分校的美国国家超级计算应用中心,将利用英伟达GH200超级芯片来构建他们的超算DeltaAI,把AI计算能力提高两倍。
此外,布里斯托大学将在英国政府的资助下,负责建造英国最强大的超级计算机Isambard-AI——将配备5000多颗英伟达GH200超级芯片,提供21 Exaflops的AI计算能力。

英伟达、AMD、英特尔:三巨头决战AI芯片
GPU竞赛,也进入了白热化。

面对H200,而老对手AMD的计划是,利用即将推出的大杀器——Instinct MI300X来提升显存性能。
MI300X将配备192GB的HBM3和5.2TB/s的显存带宽,这将使其在容量和带宽上远超H200。
而英特尔也摩拳擦掌,计划提升Gaudi AI芯片的HBM容量,并表示明年推出的第三代Gaudi AI芯片将从上一代的 96GB HBM2e增加到144GB。
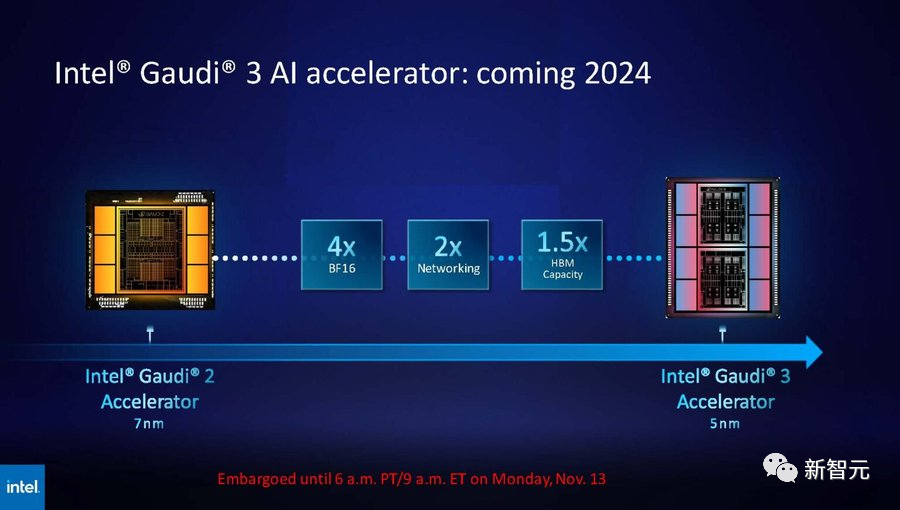
英特尔Max系列目前的HBM2容量最高为128GB,英特尔计划在未来几代产品中,还要增加Max系列芯片的容量。
H200价格未知
所以,H200卖多少钱?英伟达暂时还未公布。
要知道,一块H100的售价,在25000美元到40000美元之间。训练AI模型,至少需要数千块。
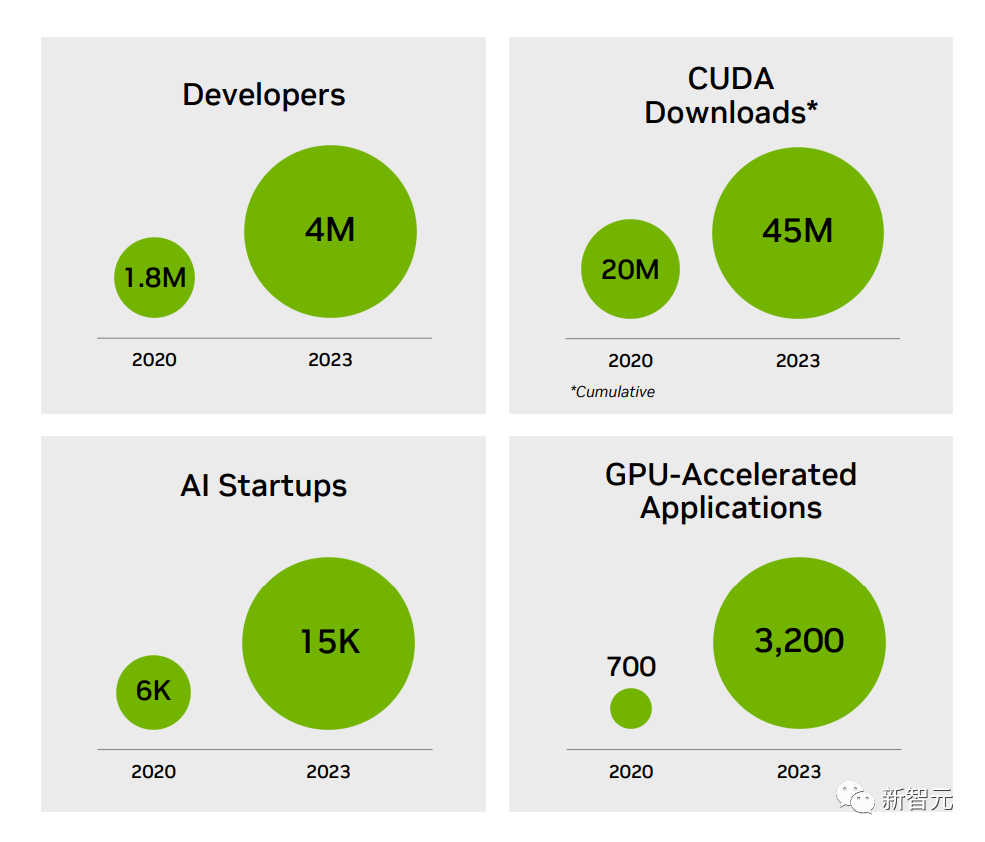
此前,AI社区曾广为流传这张图片《我们需要多少个GPU》。

GPT-4大约是在10000-25000块A100上训练的;Meta需要大约21000块A100;Stability AI用了大概5000块A100;Falcon-40B的训练,用了384块A100。
根据马斯克的说法,GPT-5可能需要30000-50000块H100。摩根士丹利的说法是25000个GPU。
Sam Altman否认了在训练GPT-5,但却提过「OpenAI的GPU严重短缺,使用我们产品的人越少越好」。
我们能知道的是,等到明年第二季度H200上市,届时必将引发新的风暴。
猜你喜欢
最新文章










- 开云体育官方版app:谁会是今年中超第一位下课的主帅?

2023-05-03 19:35:22
- 惠普今日发布了该公司的2022财年第三财季财报

2022-08-31 15:13:25
- MyFitnessPal将其流行的条形码扫描仪功能放在付费墙后面

2022-08-31 09:50:57
- 摩托罗拉系统收购无线电专家巴雷特

2022-08-30 14:12:44
- 安全hold公布2022年第二季度业绩

2022-08-29 14:47:40