
在最近的一篇论文中,苹果的研究人员宣称,他们提出了一个可以在设备端运行的模型,这个模型在某些方面可以超过 GPT-4。
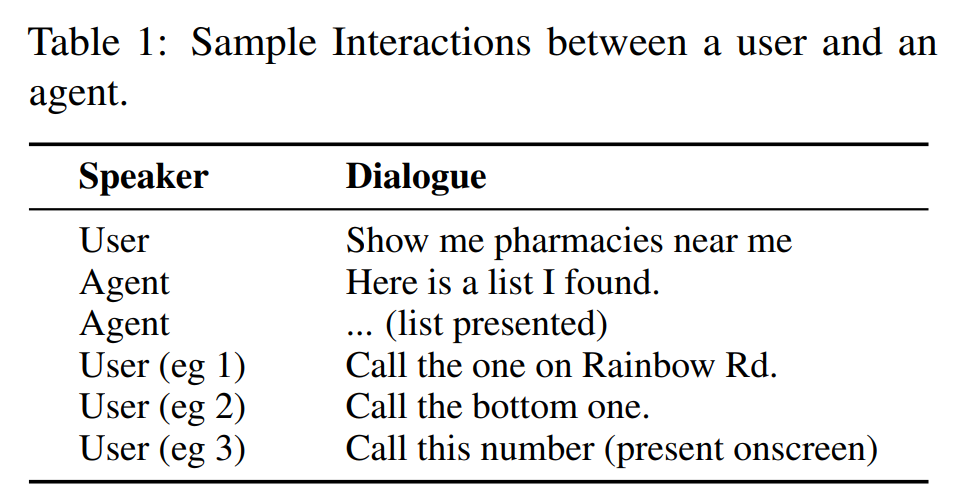
具体来说,他们研究的是 NLP 中的指代消解(Reference Resolution)问题,即让 AI 识别文本中提到的各种实体(如人名、地点、组织等)之间的指代关系的过程。简而言之,它涉及到确定一个词或短语所指的具体对象。这个过程对于理解句子的意思至关重要,因为人们在交流时经常使用代词或其他指示词(如「他」、「那里」)来指代之前提到的名词或名词短语,避免重复。
不过,论文中提到的「实体」更多得与手机、平板电脑等设备有关,包括:
屏幕实体(On-screen Entities):用户在与设备交互时,屏幕上显示的实体或信息。
对话实体(Conversational Entities):与对话相关的实体。这些实体可能来自用户之前的发言(例如,当用户说「给妈妈打电话」时,「妈妈」的联系方式就是相关的实体),或者来自虚拟助手(例如,当助手为用户提供一系列地点或闹钟供选择时)。
后台实体(Background Entities):这些是与用户当前与设备交互的上下文相关的实体,但不一定是用户直接与虚拟助手互动产生的对话历史的一部分;例如,开始响起的闹钟或在背景中播放的音乐。
苹果的研究在论文中表示,尽管大型语言模型(LLM)已经证明在多种任务上具有极强的能力,但在用于解决非对话实体(如屏幕实体、后台实体)的指代问题时,它们的潜力还没有得到充分利用。
在论文中,苹果的研究者提出了一种新的方法 —— 使用已解析的实体及其位置来重建屏幕,并生成一个纯文本的屏幕表示,这个表示在视觉上代表了屏幕内容。然后,他们对屏幕中作为实体的部分进行标记,这样模型就有了实体出现位置的上下文,以及围绕它们的文本是什么的信息(例如:呼叫业务号码)。据作者所知,这是第一个使用大型语言模型对屏幕上下文进行编码的工作。
具体来说,他们提出的模型名叫 ReALM,参数量分别为 80M、250M、1B 和 3B,体积都非常小,适合在手机、平板电脑等设备端运行。
研究结果显示,相比于具有类似功能的现有系统,该系统在不同类型的指代上取得了大幅度的改进,其中最小的模型在处理屏幕上的指代时获得了超过 5% 的绝对增益。
此外,论文还将其性能与 GPT-3.5 和 GPT-4 进行了对比,结果显示最小模型的性能与 GPT-4 相当,而更大的模型则显著超过了 GPT-4。这表明通过将指代消解问题转换为语言建模问题,可以有效利用大型语言模型解决涉及多种类型指代的问题,包括那些传统上难以仅用文本处理的非对话实体指代。

这项研究有望用来改进苹果设备上的 Siri 智能助手,帮助 Siri 更好地理解和处理用户询问中的上下文,尤其是涉及屏幕上内容或后台应用的复杂指代,在在线搜索、操作应用、读取通知或与智能家居设备交互时都更加智能。
苹果将于太平洋时间 2024 年 6 月 10 日至 14 日在线举办全球开发者大会「WWDC 2024」,并推出全面的人工智能战略。有人预计,上述改变可能会出现在即将到来的 iOS 18 和 macOS 15 中,这将代表用户与 Apple 设备之间交互的重大进步。
论文介绍

论文地址:https://arxiv.org/pdf/2403.20329.pdf
论文标题:ReALM: Reference Resolution As Language Modeling
本文任务制定如下:给定相关实体和用户想要执行的任务,研究者希望提取出与当前用户查询相关的实体(或多个实体)。相关实体有 3 种不同类型:屏幕实体、对话实体以及后台实体(具体内容如上文所述)。
在数据集方面,本文采用的数据集包含综合创建的数据或在注释器的帮助下创建的数据。数据集的信息如表 2 所示。
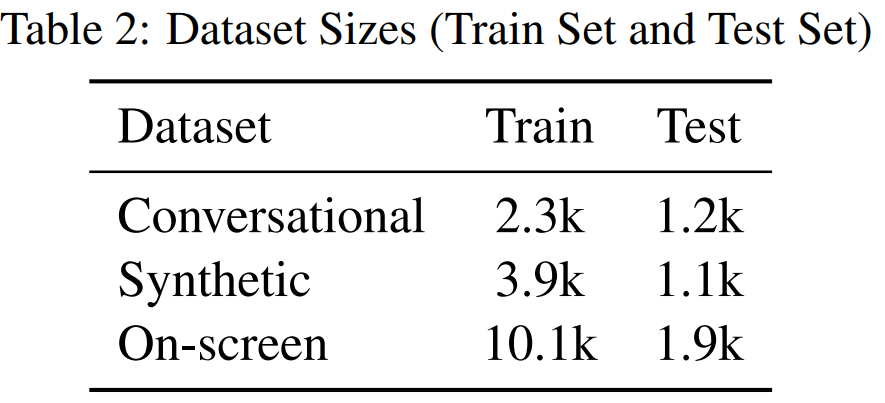
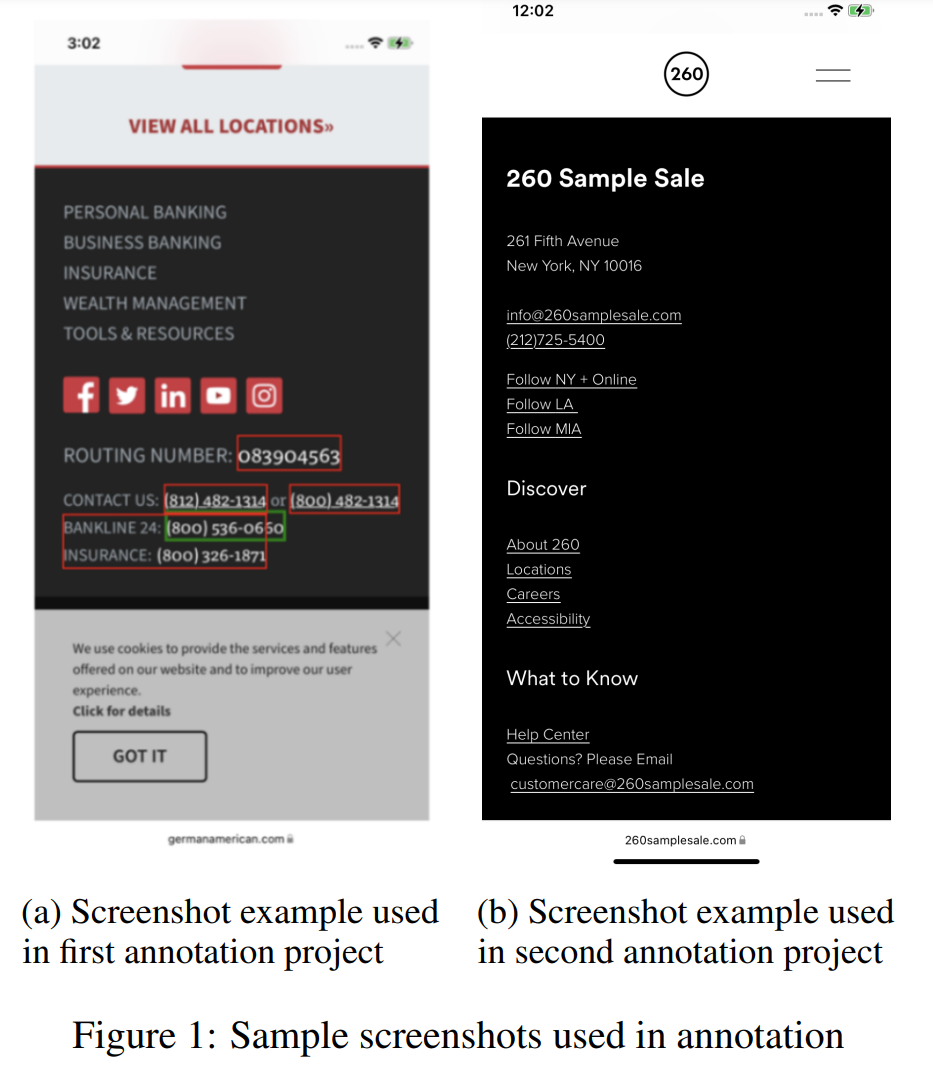
其中,对话数据是用户与智能体交互相关的实体数据;合成数据顾名思义就是根据模板合成的数据;屏幕数据(如下图所示)是从各种网页上收集的数据,包括电话号码、电子邮件等。
模型
研究团队将 ReALM 模型与两种基线方法进行了比较:MARRS(不基于 LLM)、ChatGPT。
该研究使用以下 pipeline 来微调 LLM(FLAN-T5 模型):首先向模型提供解析后的输入,并对其进行微调。请注意,与基线方法不同,ReALM 不会在 FLAN-T5 模型上运行广泛的超参数搜索,而是使用默认的微调参数。对于由用户查询和相应实体组成的每个数据点,研究团队将其转换为句子格式,然后将其提供给 LLM 进行训练。
会话指代
在这项研究中,研究团队假设会话指代有两种类型:
基于类型的;
描述性的。
基于类型的指代严重依赖于将用户查询与实体类型结合使用来识别(一组实体中)哪个实体与所讨论的用户查询最相关:例如,用户说「play this」,我们知道「this」指的是歌曲或电影等实体,而不是电话号码或地址;「call him」则指的是电话号码或联系人,而不是闹钟。
描述性指代倾向于使用实体的属性来唯一地标识它:例如「时代广场的那个」,这种指代可能有助于唯一地指代一组中的一个。
请注意,通常情况下,指代可能同时依赖类型和描述来明确指代单个对象。苹果的研究团队简单地对实体的类型和各种属性进行了编码。
屏幕指代
对于屏幕指代,研究团队假设存在能够解析屏幕文本以提取实体的上游数据检测器。然后,这些实体及其类型、边界框以及围绕相关实体的非实体文本元素列表都可用。为了以仅涉及文本的方式将这些实体(以及屏幕的相关部分)编码到 LM 中,该研究采用了算法 2。

直观地讲,该研究假设所有实体及其周围对象的位置由它们各自的边界框的中心来表示,然后从上到下(即垂直、沿 y 轴)对这些中心(以及相关对象)进行排序,并从左到右(即水平、沿 x 轴)使用稳定排序。所有位于边缘(margin)内的对象都被视为在同一行上,并通过制表符将彼此分隔开;边缘之外更下方的对象被放置在下一行,这个过程重复进行,有效地从左到右、从上到下以纯文本的方式对屏幕进行编码。
实验
表 3 为实验结果:本文方法在所有类型的数据集中都优于 MARRS 模型。此外,研究者还发现该方法优于 GPT-3.5,尽管后者的参数数量比 ReALM 模型多出几个数量级。
在与 GPT-4 进行对比时,尽管 ReALM 更简洁,但其性能与最新的 GPT-4 大致相同。此外,本文特别强调了模型在屏幕数据集上的收益,并发现采用文本编码的模型几乎能够与 GPT-4 一样执行任务,尽管后者提供了屏幕截图(screenshots)。最后,研究者还尝试了不同尺寸的模型。

分析
GPT-4 ≈ ReaLM ≫ MARRS 用于新用例。作为案例研究,本文探讨了模型在未见过领域上的零样本性能:Alarms(附录表 11 中显示了一个样本数据点)。

表 3 结果表明,所有基于 LLM 的方法都优于 FT 模型。本文还发现 ReaLM 和 GPT-4 在未见过领域上的性能非常相似。
ReaLM > GPT-4 用于特定领域的查询。由于对用户请求进行了微调,ReaLM 能够理解更多特定于领域的问题。例如表 4 对于用户请求,GPT-4 错误地假设指代仅与设置有关,而真实情况也包含后台的家庭自动化设备,并且 GPT-4 缺乏识别领域知识的能力。相比之下,ReaLM 由于接受了特定领域数据的训练,因此不会出现这种情况。

猜你喜欢
最新文章










- 开云体育官方版app:谁会是今年中超第一位下课的主帅?

2023-05-03 19:35:22
- 惠普今日发布了该公司的2022财年第三财季财报

2022-08-31 15:13:25
- MyFitnessPal将其流行的条形码扫描仪功能放在付费墙后面

2022-08-31 09:50:57
- 摩托罗拉系统收购无线电专家巴雷特

2022-08-30 14:12:44
- 安全hold公布2022年第二季度业绩

2022-08-29 14:47:40