BERT是一种基于变压器的模型,其特点是具有独特的自我关注机制,迄今为止已被证明是处理自然语言处理(NLP)任务中的递归神经网络(RNN)的有效替代方案。尽管它们具有优势,但到目前为止,很少有研究人员深入研究这些基于BERT的架构,或者试图了解其自我关注机制有效性的原因。
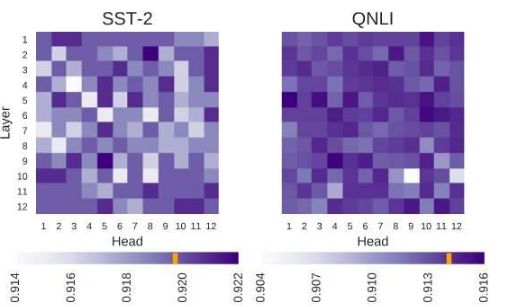
意识到文献中存在的这种差距,马萨诸塞州洛厄尔大学自然语言处理文本机器实验室的研究人员最近开展了一项研究,研究自我关注的解释,这是BERT模型中最重要的组成部分。这项研究的主要研究者和资深作者分别是Olga Kovaleva和Anna Rumshisky。他们的论文预先发布在arXiv上并将在EMNLP 2019会议上发表,它表明在不同的BERT子组件中重复有限的注意模式,暗示他们过度参数化。
“BERT是最近在NLP社区取得突破的模式,在多个任务中接管排行榜。受到这一趋势的启发,我们很想调查它是如何以及为什么有效的,”研究团队通过电子邮件告诉TechXplore。“我们希望找到自我关注,BERT主要潜在机制与给定输入文本中语言可解释关系之间的相关性。”
基于BERT的体系结构具有层结构,其每个层由所谓的“头”组成。为了使模型起作用,对这些头中的每一个进行训练以编码特定类型的信息,从而以其自己的方式对整个模型做出贡献。在他们的研究中,研究人员分析了这些个体头部编码的信息,重点关注其数量和质量。
研究人员解释说:“我们的方法专注于检查个体头部及其产生的注意模式。” “从本质上讲,我们试图回答这个问题:”当BERT对一个句子中的单个单词进行编码时,它是否会以对人类有意义的方式关注其他单词?“
研究人员使用基本的预训练和微调BERT模型进行了一系列实验。这使他们能够收集许多与基于BERT架构核心的自我关注机制有关的有趣观察。例如,他们观察到一组有限的注意模式经常在不同的头部重复,这表明BERT模型过度参数化。
“我们发现BERT往往过度参数化,并且它编码的信息存在大量冗余,”研究人员说。“这意味着训练如此大型模型的计算足迹并不合理。”
马萨诸塞州洛厄尔大学的研究人员团队收集的另一个有趣的发现是,根据BERT 模型所解决的任务,随机关闭一些头部可以改善而不是降低性能。此外,研究人员没有发现任何在确定BERT在下游任务中的表现特别重要的语言模式。
“深入学习可解释对于基础研究和应用研究都很重要,我们将继续朝着这个方向努力,”研究人员说。“最近发布了基于BERT的新模型,我们计划扩展我们的方法以对其进行调查。”
猜你喜欢
最新文章










- 惠普今日发布了该公司的2022财年第三财季财报

2022-08-31 15:13:25
- MyFitnessPal将其流行的条形码扫描仪功能放在付费墙后面

2022-08-31 09:50:57
- 摩托罗拉系统收购无线电专家巴雷特

2022-08-30 14:12:44
- 安全hold公布2022年第二季度业绩

2022-08-29 14:47:40
- Wheels Up宣布创纪录的第二季度收入同比增长49%

2022-08-29 14:11:27